2019年第八届“中国软件杯”大学生软件设计大赛
软件杯正式收官,基于深度学习的银行卡号识别系统拿了全国二等奖,精度98.6% ,相比于中科大 南航的队伍还是差了点,也没时间再去写GUI(其实是进了决赛后沉迷P5),之后会把项目工程全部开源在GitHub上,接下来准备发软件著作权专利和论文。
此次竞赛感谢所有参与提供银行卡照片的朋友,正是你们的理解与支持我们才完成了数据集的建立与定位模块的完成。感谢两位队友帮我打完了所有的数据集标签与二次标签工作,并帮我走出了低谷。感谢老板@doublezhuang提供的gtx1060显卡算力,成功在72小时内跑完了50次epoch,最后loss率为0.01%。感谢另外两支参赛队伍的相互支持,同时也祝贺你们取得佳绩。最后感谢实验室的各位学长及指导老师尤其是@Aye10032的暴力解决方案。

基于深度学习的银行卡号识别系统报告原文
摘要
针对移动终端支付时需要输入银行卡号,而银行卡号一般为12-15位,存在易忘、易错等问题,设计并完成了一种基于深度学习的银行卡号自动识别系统。该系统能够实现对银行卡号的自动识别,识别准确度达到98%以上,单张图片识别速度在0.1秒以内。该系统的图片预处理部分由opencv执行,实现对不规范银行卡图片的旋转与裁剪。卡号定位部分由SSD模型实现,使用已训练好的的模型对数字条进行定位并裁剪。在训练神经网络前,首先对官方所提供的数据集进行了数据增强与拼接,然后将增强后的80%图片用于训练,20%图片用于验证。CNN+LSTM+CTC神经网络经过训练模型loss率下降到了0.005,完成了端对端不定长的卡号识别。为了进一步验证上述模型的鲁棒性,我们自建了12-15位的各银行不同版式的共计688张银行卡数字条数据集,在实际测试中,识别率为97%。
作品技术栈介绍
本作品主要使用Python和C++两种编程语言进行项目的开发,首先使用计算机视觉库opencv进行处理,主要使用了二值化、霍夫变换直线检测、Canny边缘检测、水平投影等计算机视觉算法完成对卡号图片的预处理。其次我们通过爬虫技术扩充了整卡图片的数据库,使用标签工具软件labelImg标注数字条位置后使用SSD模型进行训练。调用SSD模型后截取出置信度最高并满足长宽比的数字条截取保存到本地文件夹。在开始识别模型训练前,首先使用了imgaug库对官方提供的数据集进行了扩充,在之后设计了CNN+LSTM+CTC网络进行模型的训练与推测。最后成果识别银行卡卡号,完成本课题要求。
本小组首先在visual studio上使用C++语言对图像定位模块进行编写与调试,之后再移植为python语言。Python环境配置由Anaconda完成,通过pip与conda完成python包管理,Pycharm与Visual Studio Code作为python开发IDE工具,git作为团队协作工具及历史代码管理工具。
项目实现思路
整体实现思路
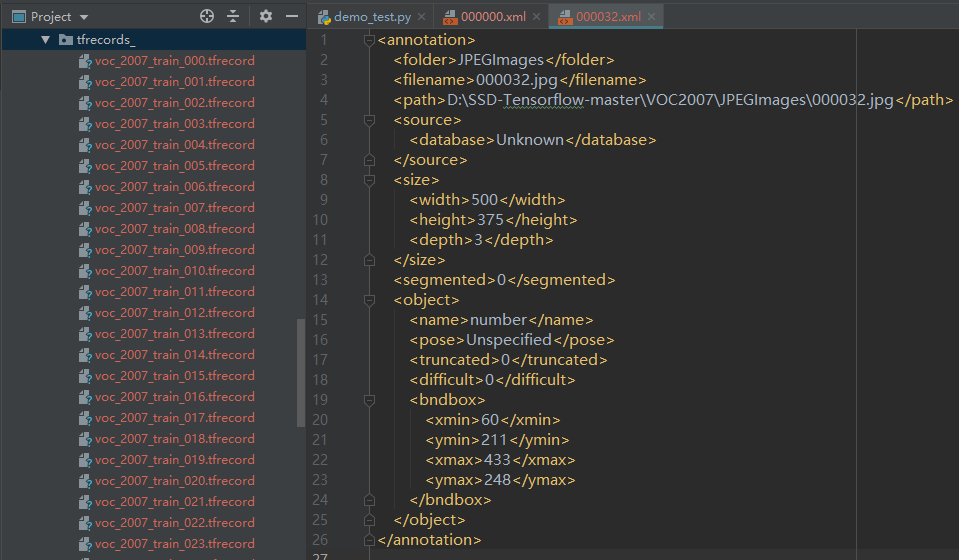
如图1所示,图片输入后,先通过opencv判断是否存在倾斜角度防止影响后续的截取图片,然后寻找图片中的银行卡轮廓减去背景对图片的影响,若寻找到轮廓即对图片进行框体裁剪。通过SSD训练好的的模型精准定位图片中数据条的位置并裁剪。最后通过调用训练好的识别模型对截取出来的数字条进行预测并输出结果,将数据结果保存到本地。
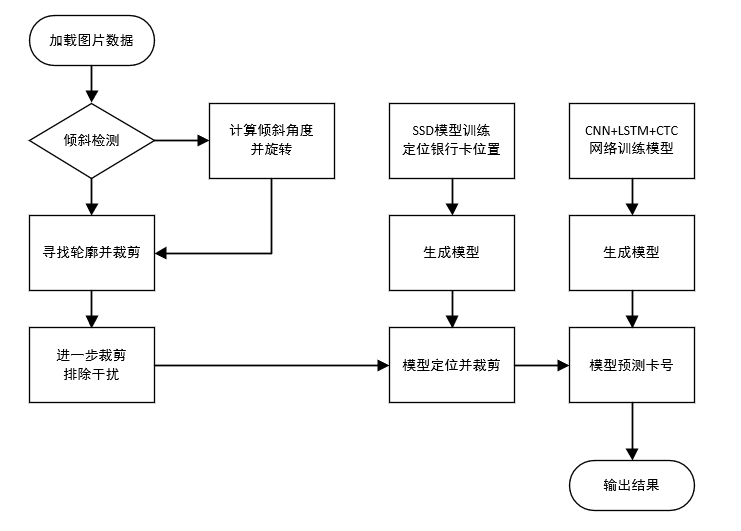
银行卡卡号定位步骤及实现思路
实现步骤:
使用灰度化、二值化、canny算子检测、矩阵旋转、findSquares、腐蚀等操作后,并通过ROI框选感兴趣区域进行第一次矫正及截取。如图2所示

以上操作都由opencv进行实现,进一步定位调用SSD训练好的模型选取置信度最高并满足长宽比例的联通区域并截取出保存到本地。如图3,图4所示。


实现思路:
在最开始的模型标记与训练中,我们尝试了标记多个4位数字连通区域,如图5所示。
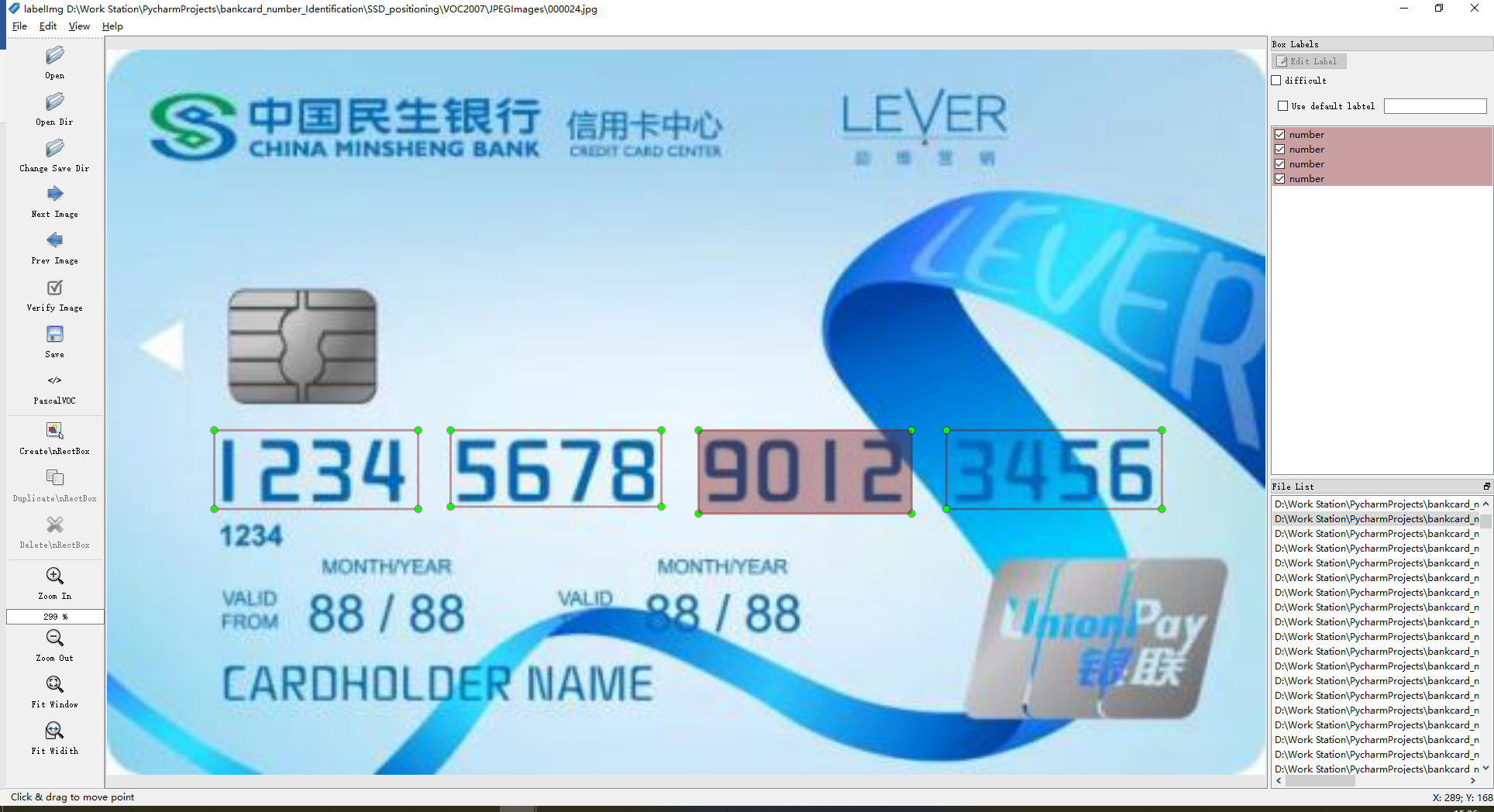
但经过实际实验发现,模型不易拟合,loss率一直不下降,在更改学习速率、损失值等指标、调整模型输入层等后仍无法获得有效的解决,验证结果如图6所示。
经过总结后我们认为,因为银行卡片版式的多样性,部分信用卡会将发卡日期、持卡人姓名也激凸印刷在卡面上,与数字区块没有太大的区别,深度学习无法很好的提取特征进行学习,同时我们没有设置负样本进行区分导致模型无法拟合。
故我们改为标记每张卡中的数字条,实际标记方法如图7所示。

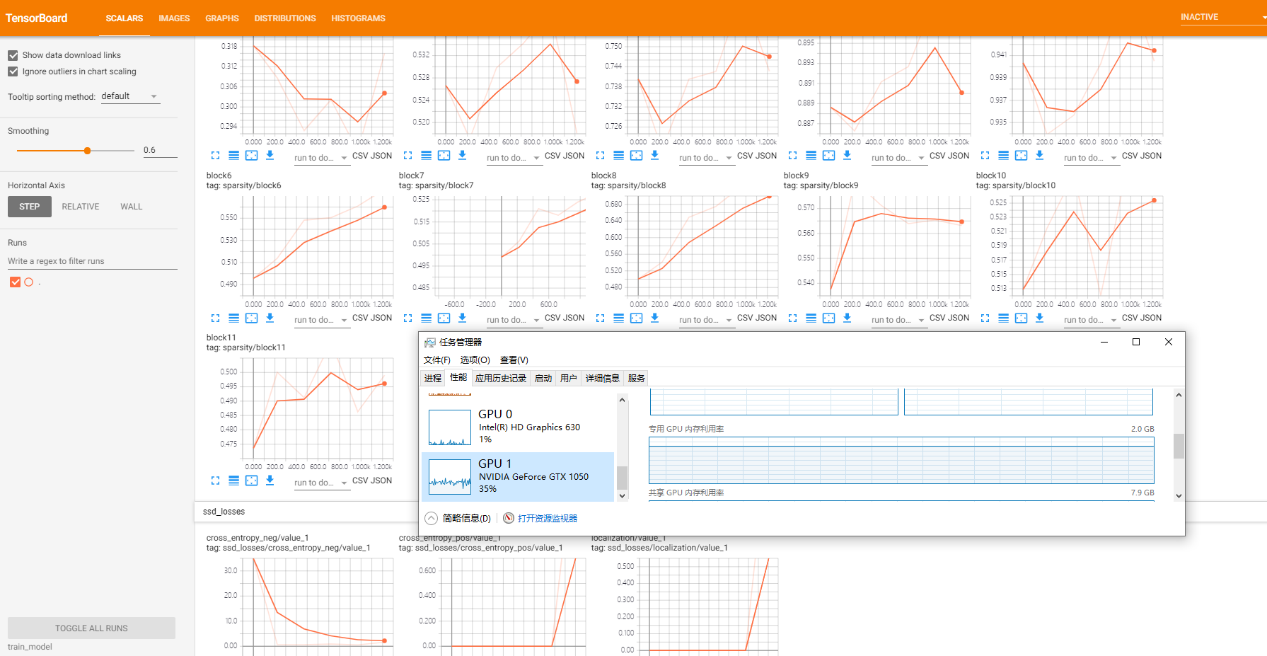
经过改进后,重新训练SSD模型,通过tensorboard可以观察到训练时关键指标loss率 acc率都以正常预期曲线下降,证明了此种改进方法是有效的并可以使模型拟合的,如图8所示。
银行卡卡号识别步骤及实现思路
实现步骤
因为在训练时我们使用的数据集是随机拼接的15-20位不定长标签的600像素x46像素图片,同时真实的银行卡数字条我们也通过opencv拉伸成了600像素x46像素图片,故在验证数据集时先将图片拉伸为600像素x46像素图片,调用之前训练好的模型,程序自动读取文件夹中数字条,将图片批量调用模型进行预测并将结果输出并保存在本地。
实现思路
我们设计了CNN+LSTM+CTC的神经网路用于不定长识别,首先我们直接使用了官方的数据集作为拓展,没有做其他更改,经过236899次迭代后模型识别正确率达到99.3%以上,平均训练损失指标为0.16%,训练日志见图9所示。
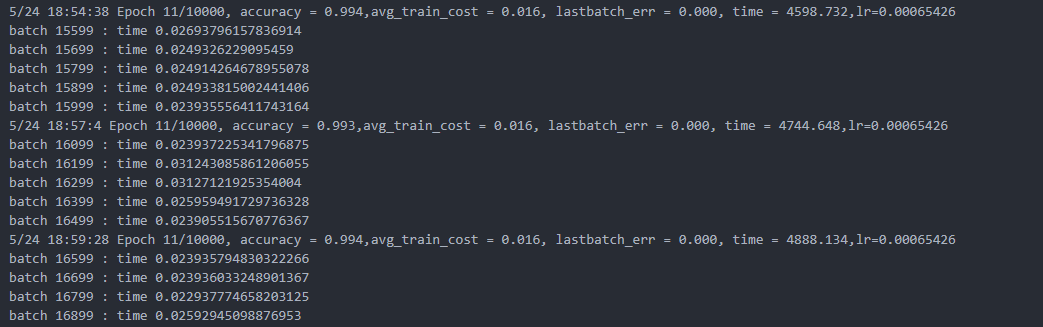
但是经过实际的测试后我们发现,在该网络层次及训练模型下,模型发生了认知偏差,认为输入图片必然为四个数字(如5864)或三个数字+一个空格(如8_57)的情况,例如输入11111的内容图片,依然识别成1111,丢失了信息,不符合实际要求。并且稍有干扰便会导致预测错误,测试失败图片如图10所示。

总结后我们认为在官方的数据集中标签都是4位,从而在训练中导致了模型过拟合,不易检出2位/3位等图片。故我们尝试了去掉标签中所有的”_”,暂时不检测空格,排除干扰的存在,如图11所示。

经过训练后,loss率、acc率正常下降,经过测试,之前无法检出的错误图片都能使用新训练好的模型成果检出,如图12所示。

在完成了训练的改进后,我们认识到在定位后截取数字条的情况下,在这模型基础上需要对数字条进行切割,但是存在类似于长数字条的情况,不易于精准切割,并且还要考虑多余数字位的处理方法,如图13所示。

我们提出的最终解决方案为,随机生成5个数字,将对应的图片与标签进行合并,生成图片大小为600*46的图片,并按顺序给予图片标签,合成方法如图14所示。
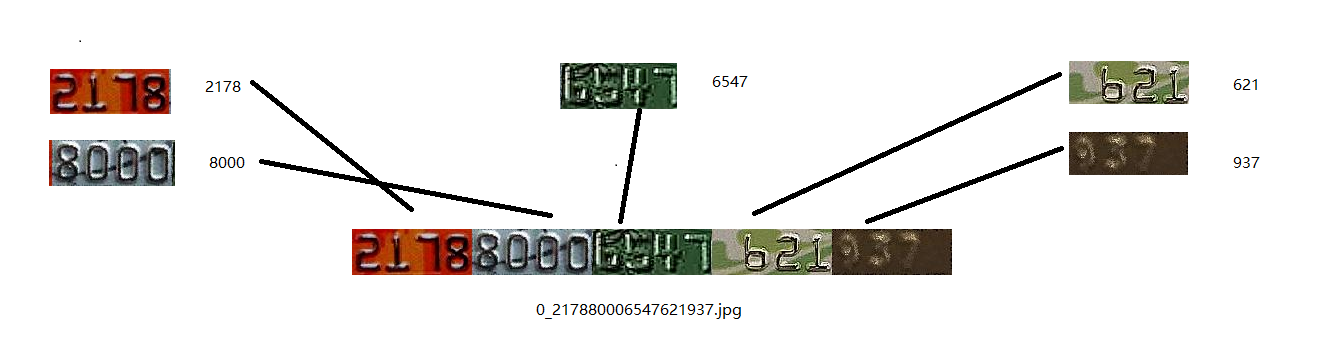
使用此种方法生成100000张图作为训练,20000张图作为验证,图片长度随机为15-20位,同时解决了过拟合的问题,同时我们引入了自建数据库,真实环境下的银行卡照片,经过搜集,共计获得739张图片,通过数据增强生成50000张图作为训练,7000张图作为验证,如图15所示。
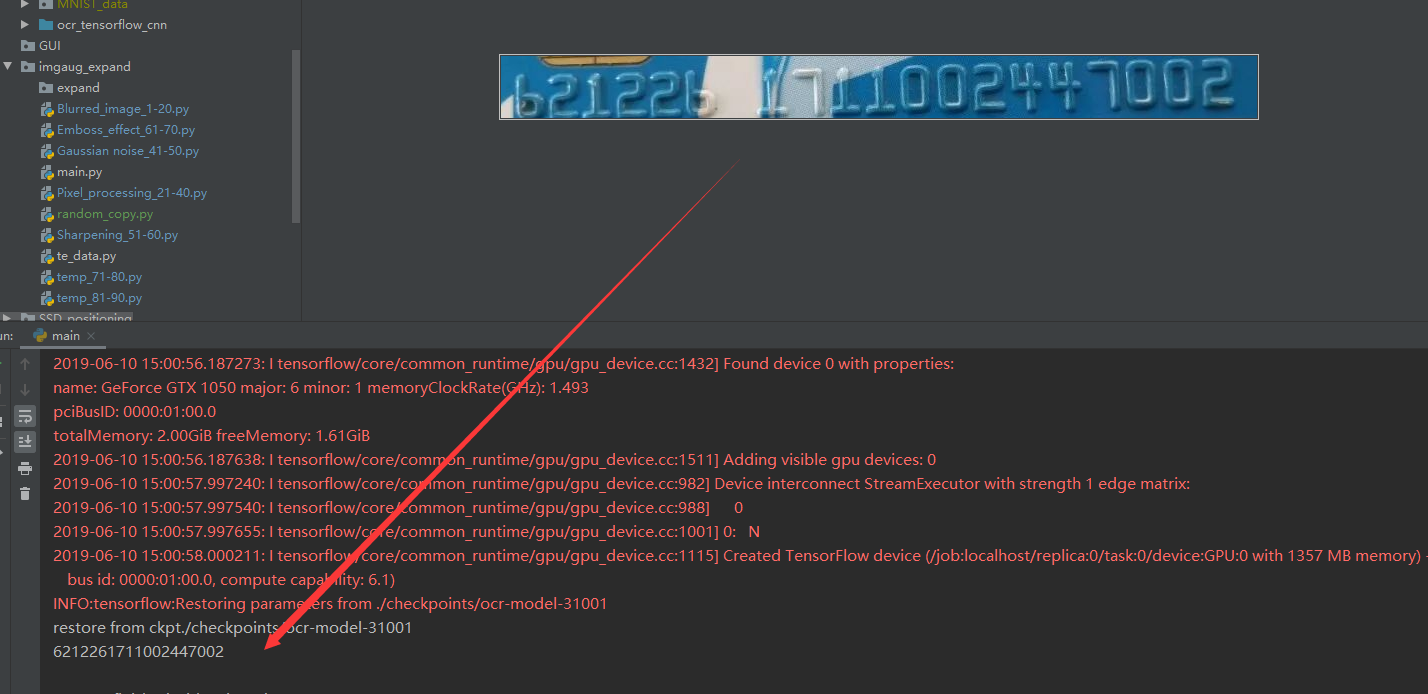
经过训练后模型正确率达到了98.7%。对数字条预测的结果如图16所示,左侧为推测结果,右侧为数字条图片,模型正确推测了数字条的银行卡号。证明了此种方法的可行性。
不定长定位&识别实现思路
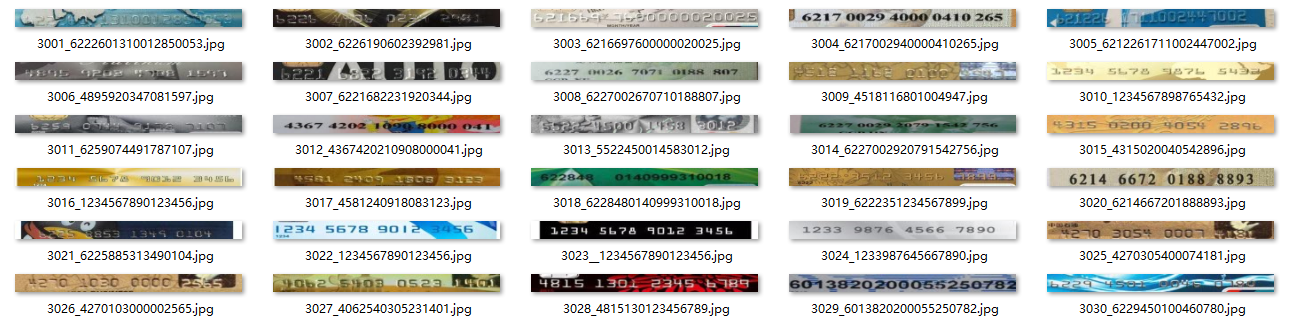
本项目针对于不定长字符的框选,首先进行了例如四位/五位的连接区域的框选,后经过实际训练发现容易造成漏检并且精度不高,不适合后续处理,故我们改为检测一整条数字条的方法,经过实际训练后发现满足需求并可以直接截取供后续识别处理。同时在识别方面我们也更改训练方式,扩充训练数据集至15-20位数字条,使模型适应数字条的检测。生成后的数据集如图17所示。

数据增强方式
本项目在处理数据集时,使用了imgaug库对原有的1084张图片进行扩充,最后共生成107316张图片供后续的样本训练。
数据集0-20为对图片进行随机0-8像素的裁剪与0-3.0的sigma图像模糊,如图18所示。

数据集21-40为对图片进行随机修改颜色,如图19所示。

数据集41-50为对图片进行添加高斯白噪声,如图20所示。

数据集51-60为对图片进行锐化操作,如图21所示。
数据集61-70为对图片进行浮雕效果操作,如图22所示。
数据集71-90为对图片进行随机加黑点噪声操作,如图23所示。

数据集91-99为对图片进行移动局部像素变换操作,如图24所示。

项目实现流程
数据预处理模块
预处理模块实现的是对倾斜图片的矫正,否则会导致后期无法正确定位及卡号预测。首先检测图片是否存在较大的倾角,使用opencv将图片进行灰度化处理,如图26所示。接下来进行二值化操作,为提取轮廓降低杂线干扰,阈值为140-255,如图27所示。使用7,7的核对图片进行高斯滤波,接着使用canny算子寻找轮廓,阈值为150-200,如图28所示。

通过以上步骤后通过霍夫直线变换方法找出图中的直线,并通过计算平均倾斜角度对图片进行旋转,效果如图29所示。接着使用findSquares方法,寻找图片中最大的矩形并截图,如图30所示,保存到本地为定位截取做准备,如图31所示。


定位模型结构&设计
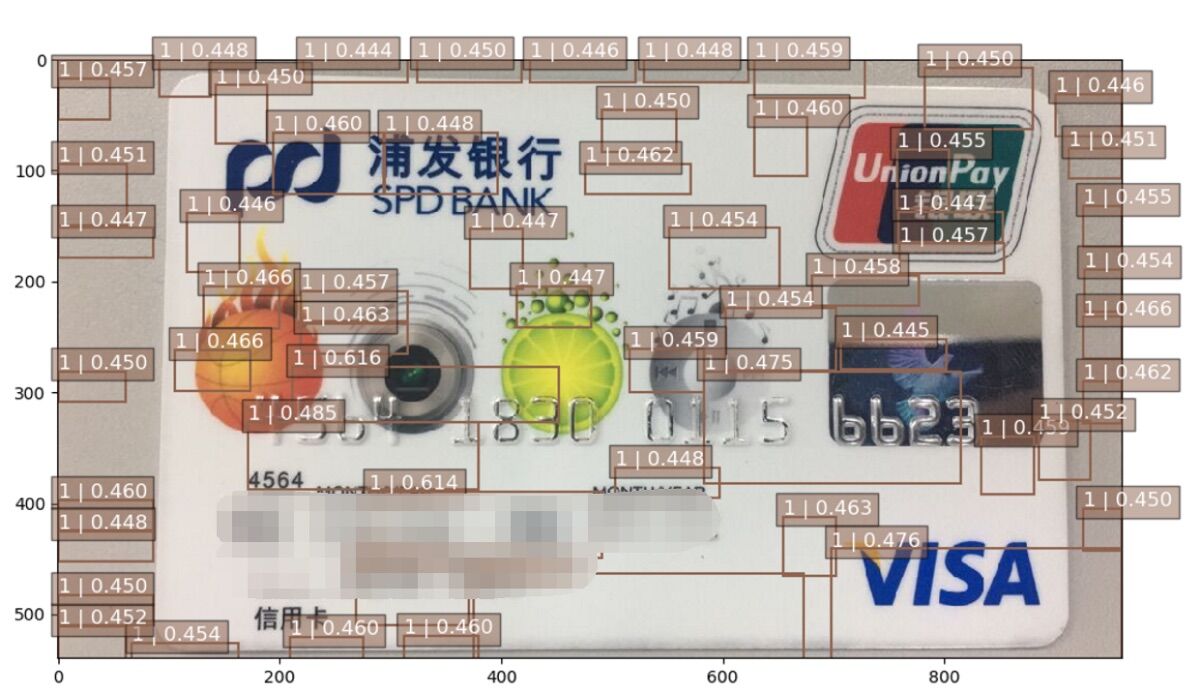
在最初我们尝试了使用opencv计算机机器视觉来定位数字条的位置,但经过实际实验后我们发现,因为银行卡版式的多样性、背景花纹的复杂难以消除、图片背景花纹比数字更清晰等问题难以精准定位数字条所在位置,如图32,图33所示。

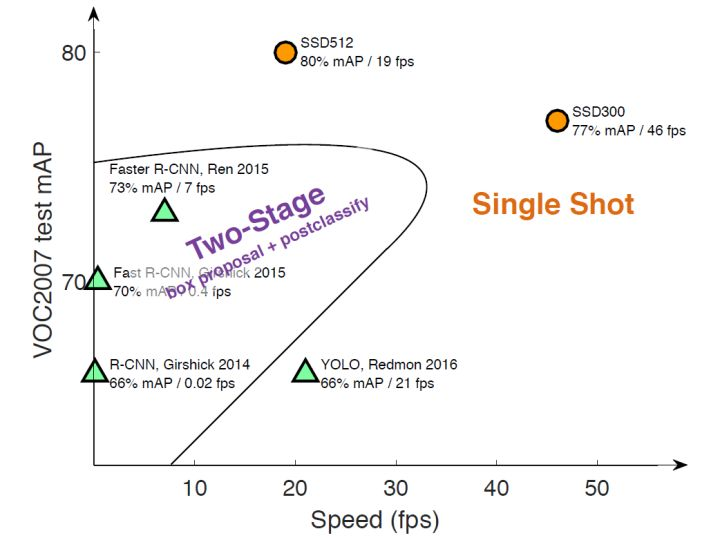
在查阅了相关资料后,目标检测近年来已经取得了很重要的进展,主流的算法主要分为两个类型(参考RefineDet):(1)two-stage方法,如R-CNN系算法,其主要思路是先通过启发式方法(selective search)或者CNN网络(RPN)产生一系列稀疏的候选框,然后对这些候选框进行分类与回归,two-stage方法的优势是准确度高;(2)one-stage方法,如Yolo和SSD,其主要思路是均匀地在图片的不同位置进行密集抽样,抽样时可以采用不同尺度和长宽比,然后利用CNN提取特征后直接进行分类与回归,整个过程只需要一步,所以其优势是速度快,但是均匀的密集采样的一个重要缺点是训练比较困难,这主要是因为正样本与负样本(背景)极其不均衡(参见Focal Loss),导致模型准确度稍低。不同算法的性能如图34所示,可以看到两类方法在准确度和速度上的差异。
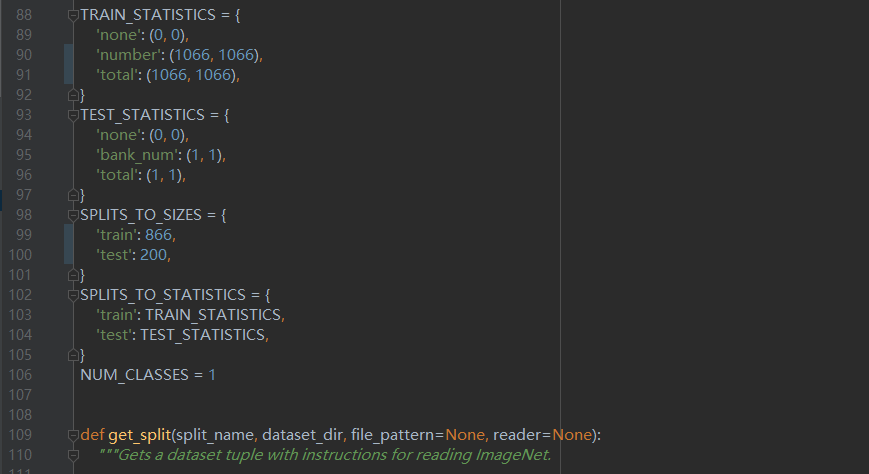
因为我们的样本数据集较少,并且长宽不固定,故我们选用了SSD模型做定位。使用了开源的SSD-tensorflow作训练,使用了官方训练好的vgg_16.ckpt作为基础模型,标记完成之生成XML后制作VOC2007数据集作为训练集,创建tfrecord文件,80%作为训练,20%作为验证,如图35所示。其次,我们将官方例程做进一步的更正,将类别区分为none与number,总样本数1066,总类数1,如图36所示。
定位模型训练过程
实际训练过程中本小组在搭载GTX1050 的个人笔记本上进行,在第一次测试的情况下,我们的数据集是由四个四个框选,导致了模型无法收敛,loss率一直不下降,具体原因已在上文中说明,这里不再赘述,定位效果如图37所示。

在更正数据集制作方法后,我们观察到数据集开始正确收敛,如图38所示。
识别训练结构&设计
因为在赛题中推荐使用端到端的解决方案,不推荐单字分割识别算法,在查阅了相关资料及文献之后,我们提出的网络结构为CNN(卷积神经网络)+LSTM(长短时记忆网络)+CTC(联结主义时间分类器)。
选用了CNN网络是因为卷积神经网络在图像和语音识别方面能够给出更好的结果。这一模型也可以使用反向传播算法进行训练。相比较其他深度、前馈神经网络,卷积神经网络需要考量的参数更少。CNN结构图如图39所示。
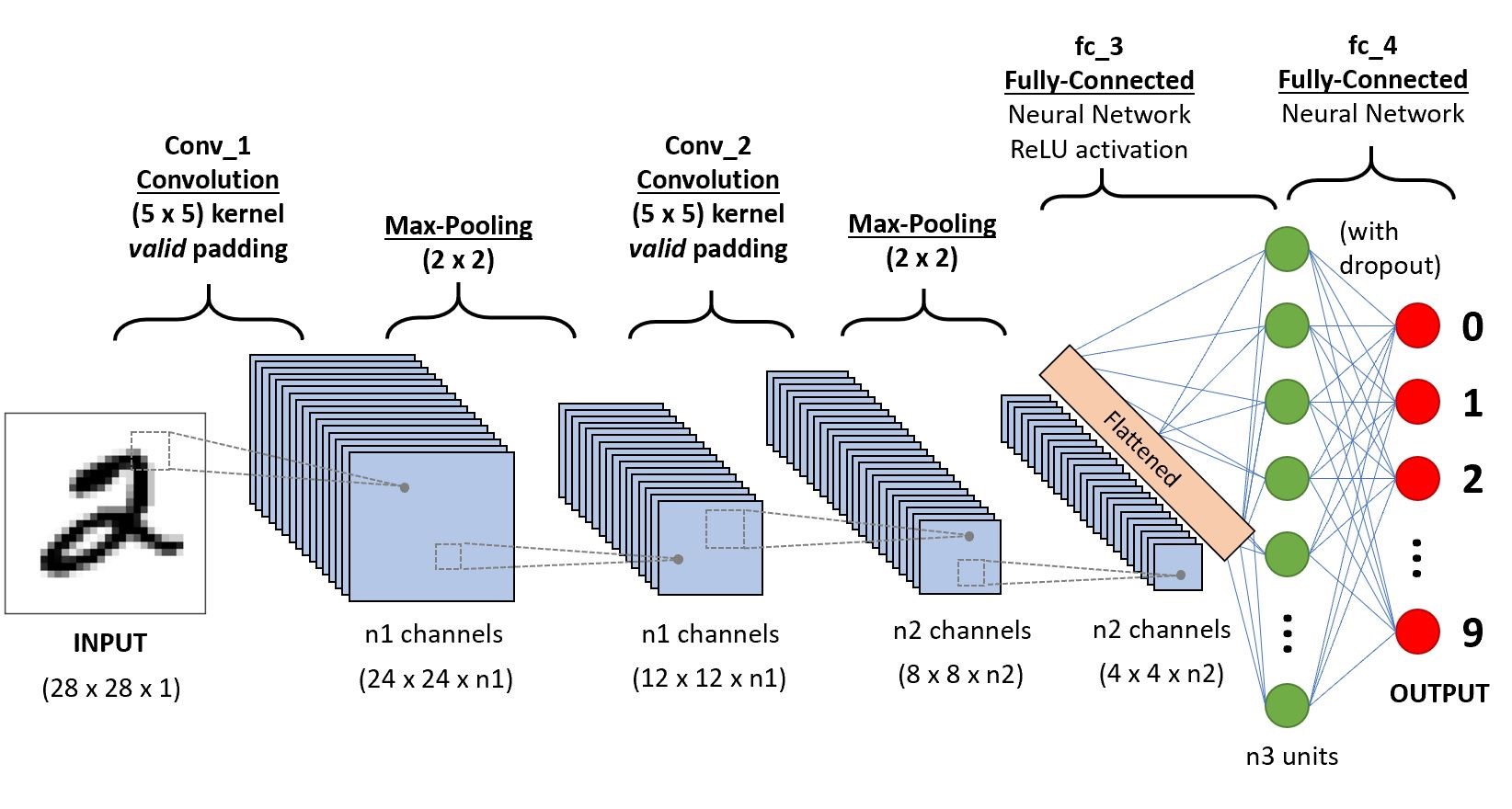
在本项目的实际使用中我们设计了四层CNN神经网络,64层CNN输出层,128层CNN隐藏层。输出层结果接入LSTM网络。
选用了LSTM因为其通过刻意的设计来避免长期依赖问题,是一种特殊的RNN,主要是为了解决长序列训练过程中的梯度消失和梯度爆炸问题。简单来说,就是相比普通的RNN,LSTM能够在更长的序列中有更好的表现。LSTM结构与普通RNN的主要输入输出区别如图40所示,LSTM状态图如图41所示。
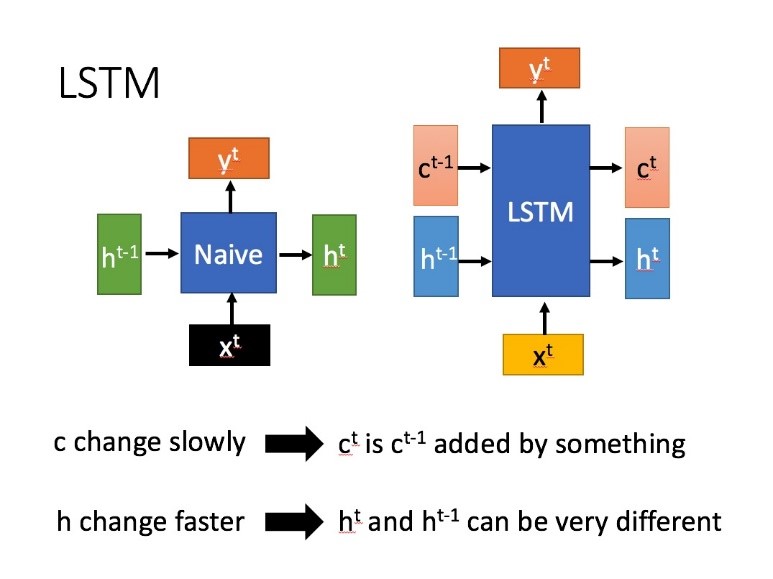
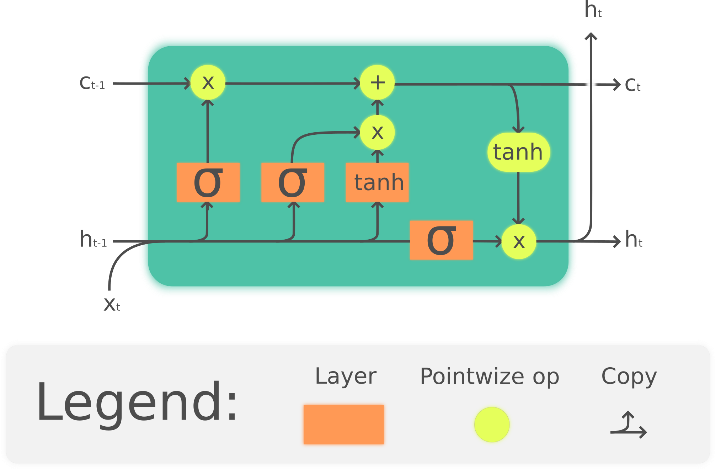
在LSTM网络中我们设置的控制输出的dropout概率为0.8,feature_w, feature_h等参数值由通过对图片进行get_shape()操作获得,首先对高阶维度转置转为二维2行1列的张量,接下来将张量转化为[FLAGS.batch_size, feature_w, feature_h * FLAGS.out_channels]的形状。初始化完之后开始进行LSTM部分训练,后接CTC网路解决切割问题。
CTC 一般译为联结主义时间分类器 ,适合于输入特征和输出标签之间对齐关系不确定的时间序列问题,CTC可以自动端到端地同时优化模型参数和对齐切分的边界。实际作用如图42所示。
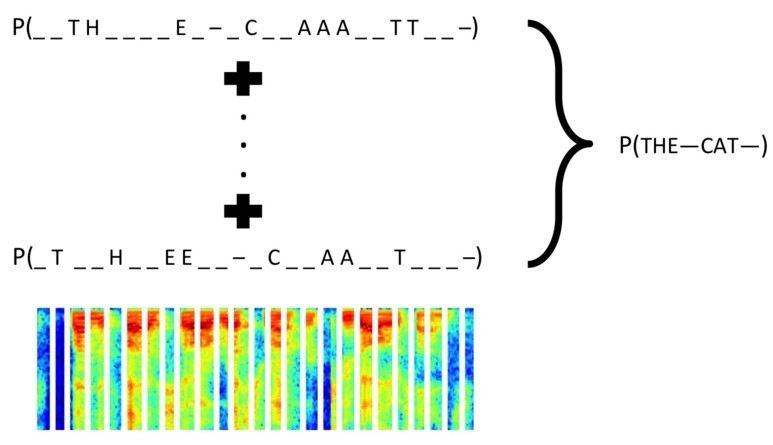
本项目采用tensorflow框架的CTC封装实现,最后的目标是最小化ctc_loss,有效提高LSTM结构的准确性。
识别模型训练过程
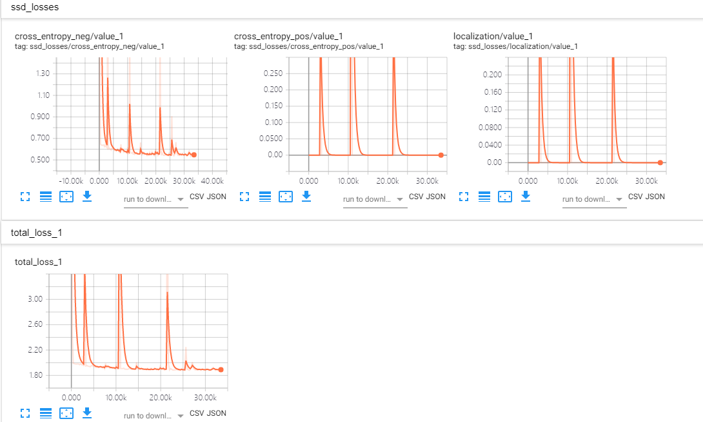
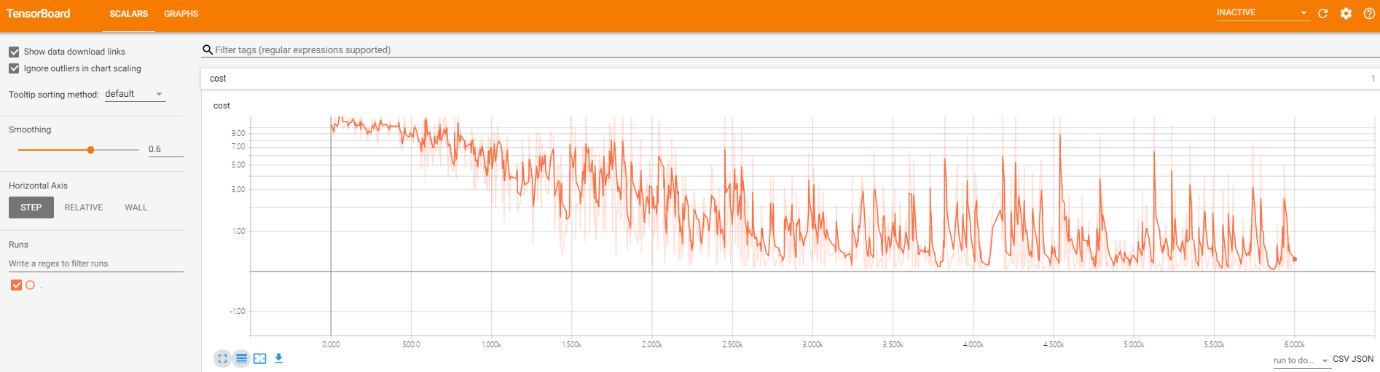
实际训练过程本小组在搭载GTX1050 的个人笔记本上进行,最后通过tensorboard与生成日志对实际训练进行分析,在CNN+LSTM+CTC网络结构下,经过10000次迭代后,loss率获得稳定下降,如图43所示。
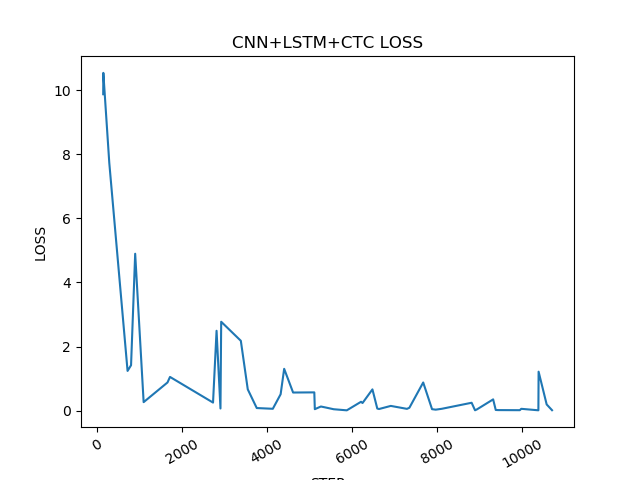
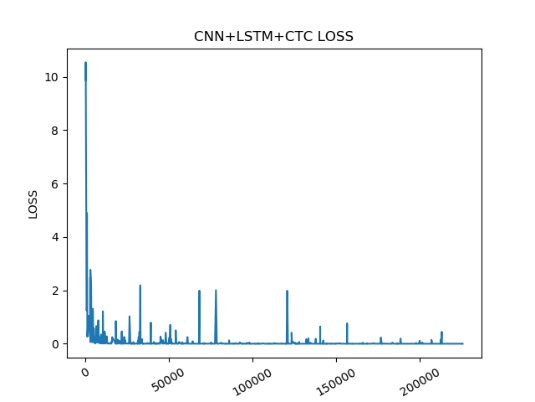
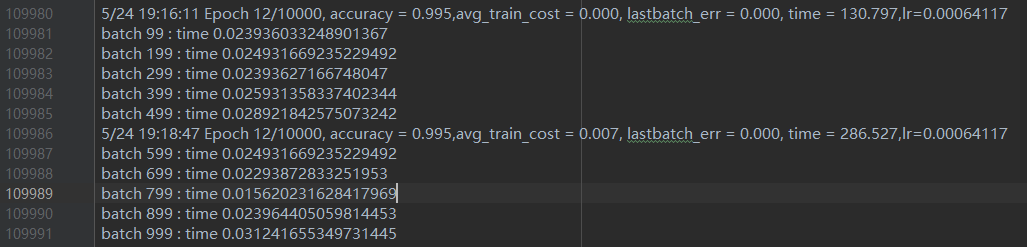
经过200000次迭代后,模型趋于稳定,loss率基本趋于0,模型训练完成,如图44所示。日志结果如图45所示,tensorboard可视化如图44所示。
结果处理
本项目为端到端的处理,模型直接预测出完整的结果,不需要做进一步的处理,直接输出并保存到本地。
结果说明
本软件在多台不同型号搭载英伟达显卡的个人笔记本与台式机上通过测试,可以成功运行软件。测试电脑型号如下:
Intel(R)Core(TM)i7-7700HQ CPU GTX1050 2GB GPU 16GB RAM Window10
Intel(R)Core(TM)i7-7700HQ CPU GTX1050TI 4GB GPU 8GB RAM Window10
Intel(R)Core(TM)i7-7700HQ CPU GTX1060 6GB GPU 16GB RAM Window10
测试数据:大赛官方提供的10张数据集+自建数据集
测试结果如表1所示:
| 数据集类型 | 定位准确率 | 注释 | 识别准确率 |
|---|---|---|---|
| 官方数据集 | 90% | 不适用 | 100% |
| 自建数据集 | 85% | 识别准确率为对数字条手动修改后 | 98% |
参考文献
[1] Shi B, Bai X, Yao C. An end-to-end trainable neural network for image-based sequence recognition and its application to scene text recognition[J]. IEEE transactions on pattern analysis and machine intelligence, 2016, 39(11): 2298-2304.
[2]孟菲. 基于 Gabor 特征的银行卡号识别算法研究[D]. 大连海事大学, 2017.
[3]董延华, 陈中华, 蔡喜欣, 等. 基于 OpenCV 的银行卡号识别算法研究[J]. 吉林师范大学学报: 自然科学版, 2017, 38(3): 120-128.
[4]杨小冬,宁新宝.自动图像识别系统图像分割算法的研究[J].南京大学学报,2004,40(4):424-431.
[5]杨芸芸. 基于拍照的银行卡卡号检测[J]. 华中科技大学, 2016: 1-z.
[6]李建华,马小妹.基于方向图的动态阕值图像图像二值化方法[J].大连理工大学学报2002,42(5):626-628.
[7]涂亚飞. 银行卡号字符的分割与识别算法研究[D]. 北京交通大学, 2017.
[8]李志森,陈晓荣.基于Halcon的银行卡卡号识别[J].电子科技,2017,30(09):56-59.
[9]卢用煌,黄山.深度学习在身份证号码识别中的应用[J].应用科技,2019,46(01):123-128.
[10]深度学习入门 基于python的理论与实践 人民邮电出版社
[11]精通数据科学:从线性回归到深度学习 人们邮电出版社
